최근 AIP-99: Common Data Access Pattern + AI에 관심을 가지게 되었습니다.
단순히 재미있어 보이는 기능이기도 하고, 개인적으로도 흥미로운 기능이라고 느껴져서요.
그래서 이 기능을 조금 더 깊게 이해해보고, 가능하다면 관련 작업에도 참여해보려고 분석을 시작했습니다.
그런데 지난 밋업 네트워킹 시간에 몇 분이 제가 Airflow에 어떤 방식으로 기여를 진행하는지 궁금하다고 질문해주셨는데요.
그래서 이번 기회에 제가 Airflow 작업을 시작할 때 어떤 방식으로 접근하는지를 글로 한번 정리해보려고 합니다.
생각해보니 저는 보통 세 가지 방식으로 작업을 시작합니다.
- 올라온 이슈 중 관심 있는 부분이나 문제를 발견하여 기여
- 기존에 알고 있던 코드에서 미뤄두었던 문제를 해결하는 기여
- 진행 중인 AIP를 보고, 함께 작업하며 배울 수 있는 부분이 있는지 찾아보고 기여
1번은 비교적 단순합니다. 관심 있는 이슈를 찾아 바로 작업을 시작하거나 문제가 있는 부분을 개선하면 되니까요.
2번은 조금 다릅니다. 기존에 코드베이스를 살펴보다 보면 여러 이유로 미뤄져 있는 작업들이 있습니다.
우선순위에서 밀렸거나, 지금 변경하기에는 너무 큰 작업이라 작은 가지부터 해결하기로 합의된 경우도 있습니다.
그래서 오늘은 3번, 진행 중인 AIP를 보고 제가 어떤 방식으로 접근하고 분석하는지를 천천히 공유해보려고 합니다.
기능의 방향 알기
새로운 기능에 기여하려면 먼저 이 기능의 목적과 방향을 이해해야 한다고 생각합니다.
그래야 새로운 기능을 추가하거나 제안을 할 때 그 방향에 맞춰 작업할 수 있기 때문입니다.
이 목적과 방향을 이해하기 위해서는 AIP(Airflow Improvement Proposal) 를 살펴보는 것이 가장 좋습니다.
AIP 문서에서는 이 제안이 등장하게 된 배경과 해결하려는 문제, 그리고 어떤 방향으로 발전하려는지를 확인할 수 있습니다. 또한 관련 토론과 합의된 내용들도 함께 살펴볼 수 있습니다.
그래서 저는 관심 있는 기능이 생기면 먼저 AIP 문서를 읽어보는 편입니다.(메일링 리스트도 보긴하는데 글이 너무 길어질 것 같아서 여기서는 간략히만 정리하겠습니다.)
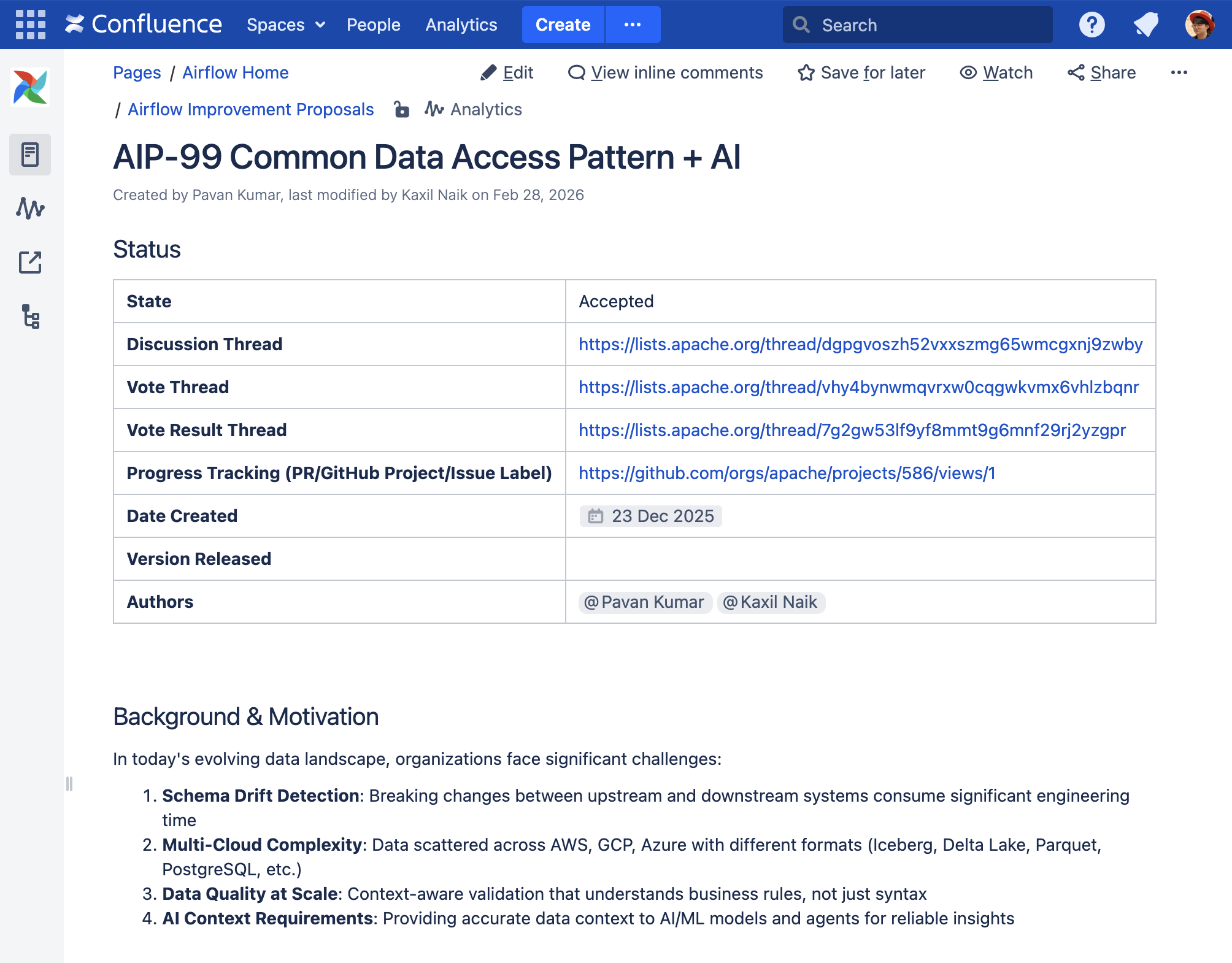
이번에 살펴본 것은 AIP-99 입니다.
AIP 제목은 “Common Data Access Pattern + AI” 입니다.
AIP-99의 동기
AIP-99에서는 최근 데이터 환경에서 다음과 같은 문제들이 있다고 설명합니다.
스키마 변경 감지
업스트림과 다운스트림 시스템 사이에서 스키마가 변경되면서 파이프라인이 깨지는 문제가 자주 발생합니다.
이러한 문제는 생각보다 많은 운영 시간을 소모하게 됩니다.
멀티 클라우드 환경의 복잡성
데이터가 여러 환경에 분산되어 있습니다. 예를 들어 AWS, GCP, Azure와 같은 다양한 클라우드 환경에 데이터가 존재합니다.
또한 데이터 포맷도 Parquet, Delta Lake, Iceberg, JSON, CSV 등 매우 다양합니다.
대규모 데이터 품질 관리
데이터 규모가 커질수록 수작업으로 데이터 품질 검증을 관리하기 어려워집니다. 특히 단순한 문법 검증이 아니라 비즈니스 맥락을 이해하는 검증이 필요해지는 상황입니다.
AI 컨텍스트 요구 사항
AI나 ML 모델, 그리고 에이전트가 신뢰할 수 있는 결과를 만들기 위해서는 데이터 스키마, 데이터 타입, 샘플 데이터와 같은 정확한 데이터 컨텍스트가 필요합니다.
정리해보면 AIP-99는 다음과 같은 문제를 해결하려고 합니다.
- 데이터 생산자와 소비자 사이의 스키마 불일치로 인해 발생하는 파이프라인 실패 문제
- 데이터 규모가 커질수록 한계에 도달하는 수작업 데이터 품질 검증 문제
- 여러 클라우드와 데이터 포맷을 다루기 위한 도구가 파편화된 문제
- 단순 문법 검증이 아니라 비즈니스 맥락을 이해하는 데이터 검증의 필요성
AIP-99 의 핵심 아이디어
AIP-99의 핵심은 한 마디로 정리할 수 있습니다.
“Airflow에 LLM 기반 데이터 작업 Operator를 도입하자.”
그리고 Airflow가 기존에 가지고 있는 강력한 기능들을 적극적으로 활용합니다.
- Connection
- Hook
- Asset
- XCom
즉 Airflow의 기존 생태계를 AI가 활용할 수 있도록 만드는 접근이라고 볼 수 있습니다.
제안된 주요 Operator
AIP에서는 몇 가지 LLM 기반 Operator를 제안하고 있습니다.
LLMSQLQueryOperator
자연어를 SQL로 변환합니다.
예를 들어 다음과 같은 요청을 SQL로 변환합니다.
최근 30일 동안 주문을 하지 않은 고객을 찾아줘
LLMSchemaCompareOperator
여러 데이터 시스템 간 스키마를 비교합니다.
예를 들어 다음과 같은 시스템 간 비교가 가능합니다.
- S3
- PostgreSQL
- Snowflake
LLMDataQualityOperator
데이터 품질 검증 쿼리를 자동으로 생성합니다.
예를 들어 다음과 같은 검증 규칙을 정의할 수 있습니다.
price 컬럼의 값이 0이 아닌지 검증
LLMFileAnalysisOperator
파일 기반 데이터를 분석하는 작업을 수행합니다.
이 AIP에서 흥미로운 부분
이 AIP를 보면서 개인적으로 흥미롭게 느낀 부분도 몇 가지 있었습니다.
Context-aware LLM
LLM에게 자동으로 다양한 데이터 컨텍스트가 제공됩니다.
예를 들어 다음과 같은 정보입니다.
- table schema
- sample data
- database version
- SQL dialect
이러한 정보를 기반으로 LLM이 데이터를 이해한 상태에서 작업을 수행하게 됩니다.
Built-in Safety
LLM이 위험한 SQL을 생성하지 못하도록 제한하는 규칙이 포함되어 있습니다.
예를 들어 다음과 같은 SQL은 생성되지 않도록 제한됩니다.
DROP
TRUNCATE
DELETE without WHERE
ALTER
AI 기반 시스템에서 이러한 안전장치를 기본 설계에 포함한 점이 인상적이었습니다.
구조화된 LLM 실행
AIP-99에서는 LLM 호출을 단순한 문자열 생성이 아니라 구조화된 방식으로 처리하려는 접근도 포함되어 있습니다.
여기서 활용되는 기술 중 하나가 PydanticAI 입니다.
PydanticAI는 LLM의 입력과 출력을 Pydantic 모델 기반으로 구조화할 수 있게 해주는 라이브러리입니다.
예를 들어 LLM 결과를 다음과 같은 구조로 받을 수 있습니다.
{
"query": "...",
"tables_used": ["customers", "orders"],
"risk_level": "low"
}
이렇게 하면 Airflow task에서 LLM 결과를 더 안정적으로 처리할 수 있습니다.
DataFusion 기반 통합 Query
AIP에서는 AnalyticsOperator라는 새로운 Operator도 제안하고 있습니다.
이 Operator는 여러 스토리지를 하나의 SQL로 조회할 수 있도록 합니다.
예를 들어 다음과 같은 스토리지입니다.
- S3
- GCS
- Azure Blob
여기서 사용하는 엔진이 Apache DataFusion 입니다.
Spark 같은 무거운 엔진 없이도 단일 노드에서 빠르게 분석을 수행할 수 있다는 점이 흥미로운 부분입니다.
Human-in-the-loop
AI가 생성한 결과를 사람이 검토하는 단계를 워크플로우 안에 포함할 수 있습니다.
예를 들어 다음과 같은 흐름입니다.
LLM SQL 생성
↓
사람이 검토 & 승인
↓
Query 실행
AI 기반 워크플로우에서 사람의 검토 단계를 자연스럽게 포함할 수 있다는 점이 흥미로운 설계라고 느꼈습니다.
구현 전략
AIP-99의 구현 전략도 인상적인 부분이었습니다.
Phase 1
먼저 provider 형태로 기능을 구현합니다.
apache-airflow-providers-ai
이 단계에서는 빠르게 실험하고 반복하기 위해 Airflow Core를 변경하지 않는다고 합니다.
Phase 2
기능 확장 단계라고 합니다.
- Human-in-the-loop 개선
- 성능 최적화
Phase 3
필요할 경우 Core 수준의 변경도 검토될 수 있습니다.
마무리
제가 파악해봤을 때, 현재 상황을 살펴보면 Phase 1은 완료된 것으로 보이고, Human-in-the-loop 관련 작업이 진행되는 Phase 2 단계 정도로 보입니다.
그래서 Phase 1에서 진행된 작업들을 먼저 살펴보고, Phase 2에서 제가 기여해볼 수 있는 작업이 있는지도 찾아보려고 합니다.
저는 AIP 관련 작업은 이렇게 시작하는 편이지만, 물론 사람마다 성향이 다르기 때문에 정답은 아닐 수 있습니다.